-
La semaine dernière, nous avons écrit le script pour traiter des corpus japonais.
Cependant, ce script n'a pas marché pour tout le monde et chaque personne a un problème différent.
Heureusement, nous avons pu résoudre les problèmes de chaque côté, nous allons donc montrer les manières de résoudre les problèmes !
le problème était que :
Pour résoudre ce problème, nous avons eu 2 manières.
La première manière est que nous avons importé " io " et nous avons écrit " io.open " au lieu d'écrire seulement " open " dans le fichier de japonais.py.
Voici le nouveau script:
La deuxième manière est que après avoir importé "io", nous avons ajouté " -sig " après UTF-8 pour "entree".
Voici le nouveau script :
Enfin, nous avons inséré nos scripts de "japonais.py" et "chinois.py" dans le script de bash comme suivant :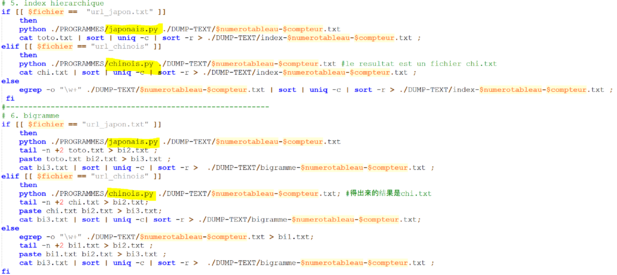
Chinatsu, Mei et Anaëlle.
また来週 ! votre commentaire
votre commentaire
-
Le japonais n'ayant pas d'espace comme en français, l'expression régulière "\w+" ne peut pas reconnaître correctement les mots japonais. Nous devons donc utiliser une autre méthode pour segmenter nos textes japonais.
Nous avons trouvé cette méthode sur un des blogs des années précédentes et avons donc d'utiliser l'outil Janome.

Ensuite nous avons créer un fichier texte avec un petit texte japonais trouvé sur internet pour le tester : 田中さんは英語の学生です。毎日英語を習います。毎朝6時半に起きます。シャワーをあびます。そして朝ご飯を食べます。朝ご飯の後で歯をみがきます。7時半に家を出ます。
Voici le script lancé :
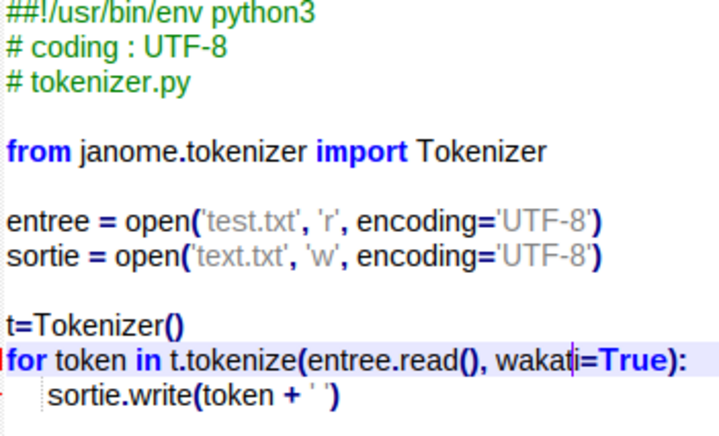
Et voici le résultat !
田中 さん は 英語 の 学生 です 。 毎日 英語 を 習い ます 。 毎朝 6 時半 に 起き ます 。 シャワー を あび ます 。 そして 朝 ご飯 を 食べ ます 。 朝 ご飯 の 後 で 歯 を みがき ます 。 7 時半 に 家 を 出 ます 。
Ce résultat nous satisfait et nous allons donc l'utiliser dans notre script. Nous l'avons légèrement modifié pour avoir un mot par ligne:

Chinatsu, Mei et Anaëlle.
À la prochaine !
votre commentaire
français, anglais, japonais et mandarin









